It is about time to say something again about how the project is going. First of all, as a matter of excuse (probably a bad one though) I want to say why the blog has not been updated lately. There have been a couple of weeks in which I have been debugging the code for the primal formulation of the SO-SVM based on MOSEK using a simple multiclass classification example. Those two weeks were basically that, debugging testing, debugging again, testing, … it is not interesting stuff to tell the truth but very necessary in any case! However, last week I started to work in the – probably – most interesting part of the project, the Hidden Markov – Support Vector Machine [1].
I like to think of HM-SVMs as a particular instance of the general Structured Output (SO) problem I have been talking about in the previous posts. In SO learning we are trying to find a function  that takes an object from the space
that takes an object from the space  and outputs and object from the space
and outputs and object from the space  . In HM-SVMs the objects of are sequences of discrete data (e.g. integers). In order to deal with the structure of the sequences properly, we extract features of the data in the space together with the data in the space . This is done via a function we denote as
. In HM-SVMs the objects of are sequences of discrete data (e.g. integers). In order to deal with the structure of the sequences properly, we extract features of the data in the space together with the data in the space . This is done via a function we denote as  whose definition appears in the tutorial about HM-SVM that Nico, my GSoC mentor, wrote [2, pages 4 and 5].
whose definition appears in the tutorial about HM-SVM that Nico, my GSoC mentor, wrote [2, pages 4 and 5].
Another important piece of the SO-SVM is the argmax function. In HM-SVMs this function is computed using the well-known Viterbi algorithm. I had never studied before this algorithm but I was happy to discover its similar structure to the forward-backward algorithm used to train an HMM from data that I have already studied and implemented [3]. I found this tutorial [4] on the Viterbi algorithm very useful and easy to understand. The implementation I have done in SHOGUN of this algorithm is based on the one in the HMSVM toolbox [5] (in particular, it is in this file [6]).
One more piece of code I have implemented in the toolbox for the HM-SVM is the loss function, commonly denoted as  . In this case, we use the Hamming distance defined for strings. In our case, the inputs of the loss function are sequences of the same length so the Hamming loss is simple the count of the number of elements that are different in the sequences (think of it as the minimum number of modifications one may do to one of the sequences to make it equal to the other. Providing that the sequences are of the same length, the only modification allowed is to change the value of an element in one of the sequences).
. In this case, we use the Hamming distance defined for strings. In our case, the inputs of the loss function are sequences of the same length so the Hamming loss is simple the count of the number of elements that are different in the sequences (think of it as the minimum number of modifications one may do to one of the sequences to make it equal to the other. Providing that the sequences are of the same length, the only modification allowed is to change the value of an element in one of the sequences).
These three functions, together with some data structures to hold features and labels used by the HM-SVM, constitute what I have implemented so far into SHOGUN about this interesting discriminative model. The plan now is to correct with Nico the possible mistakes I have introduced into the code and to generate some training and test data so I can start debugging phase! My idea is to port this function [7] from HM-SVM toolbox that generates random two-state data.
Comments and suggestions are very welcome!
You can find the code I have been talking about in github:
https://github.com/iglesias/shogun/tree/so/src/shogun/
(mainly in the files structure/HMSVMModel.[cpp|h], features/MatrixFeatures.[cpp|h], structure/HMSVMLabels.[cpp|h]).
References
[1] Altun, Y., Tsochantaridis, I., Hofmann, T. Hidden Markov Support Vector Machines.
http://cs.brown.edu/~th/papers/AltTsoHof-ICML2003.pdf
[2] SHOGUN Hidden Markov SO-SVM written by Nico Görnitz.
https://dl.dropbox.com/u/11020840/shogun/hmsvm.pdf
[3] The code of my HMM implementation for one of the homeworks of the Artificial Intelligence course that I took at KTH. https://github.com/iglesias/hmm-ai-ducks
[4] Viterbi algorithm tutorial.
http://www.comp.leeds.ac.uk/roger/HiddenMarkovModels/
html_dev/viterbi_algorithm/s1_pg2.html
[5] Entry in mloss.org for the HM-SVM toolbox written by Gunnar Raetsch and Georg Zeller.
http://mloss.org/software/tags/hmsvm/
[6] Viterbi algorithm implementation in the HM-SVM toolbox.
https://dl.dropbox.com/u/11020840/shogun/best_path.cpp
[7] Data generation for a two-state model in the HM-SVM toolbox.
https://dl.dropbox.com/u/11020840/shogun/simulate_data.m
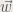 was zero for every problem instance. After double checking with MATLAB’s function quadprog that the correct solution for the problem was effectively non-trivial, I tried adding some lines here and there to ensure that the parameters given to MOSEK’s were the correct ones. All the matrices and vectors were ok. After some more lines to print out the bounds of the problem I found it. The variables of the optimization problem were all fixed to zero!
was zero for every problem instance. After double checking with MATLAB’s function quadprog that the correct solution for the problem was effectively non-trivial, I tried adding some lines here and there to ensure that the parameters given to MOSEK’s were the correct ones. All the matrices and vectors were ok. After some more lines to print out the bounds of the problem I found it. The variables of the optimization problem were all fixed to zero! . However, this is false. If no bound is given, then the reality is that MOSEK fixes the value of the variable to zero. I still don’t get the point of including variables to the optimization vector whose values are fixed… but that’s another story.
. However, this is false. If no bound is given, then the reality is that MOSEK fixes the value of the variable to zero. I still don’t get the point of including variables to the optimization vector whose values are fixed… but that’s another story.
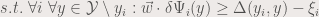

 for the QP with box constraints). I have started to write some code in CPrimalMosekSOSVM that makes use of MOSEK to solve the QP. This piece of code is still rather poor and it is just in my local repository.
for the QP with box constraints). I have started to write some code in CPrimalMosekSOSVM that makes use of MOSEK to solve the QP. This piece of code is still rather poor and it is just in my local repository. computation and another one for the structured loss function
computation and another one for the structured loss function  .
.